Abstract, Harr-feature와 Integral Image는 이전 포스팅을 참고해주세요!
[정리]Rapid object detection using a boosted cascade of simple features(Viola-Jones algorithm) -1
Rapid object detection using a boosted cascade of simple features [안면 감지(검출)을 위한 알고리즘] -Paul Viola and Michael Jones 얼굴 인식을 위해 이미지나 영상에서 얼굴이 감지되는 작업이 선행되어야..
studyingfox.tistory.com
Learning Classification Functions
AdaBoost
AdaBoost는 Adaptive+Boosting의 약자로, 엄청난 feature들 가운데서 가장 나은 feature를 찾는데 도움을 주는 머신러닝 알고리즘이다.
간단하게 설명하자면, weak classifier(약한 분류기)에 가중치들이 부여되고, 이 가중치가 부여된 weak classifier들이 결합해 strong classifier(강한 분류기)를 생성하게 되는 기법이다. 일종의 ensenble(앙상블)기법으로, 집단지성을 이용해 더욱 똑똑한 classifier를 만드는 것이다.
여기서 결합은 선형 결합(linear conbination)의 형태로 이루어지며, 수식은 다음과 같다.

F(x)는 strong classifier, f(x)는 weak classifier이다.
그렇다면 왜 Adaptive인가?
AdaBoost는 이전의 classifier에 의해 잘못 분류된 것들을 이어지는 weak classifier들이 수정하며 이전에 처리되지 못한 것들을 더 잘 분류할 수 있게 적응해가기 때문이라고 한다.
논문에서는 기존 AdaBoost가 weak classfier의 classification 성능을 높이는 것을 목적으로 하는 것을 조금 변형하여
Adaboost 알고리즘이 적은 feature set을 선택하고 classifier를 훈련시키는데 사용한다.
이는 모든 rectangle feature(앞서 설명한 harr-feature)를 연산하는 것은 엄청난 비용 손실이기 때문에
적은 feature set을 선택해 이들이 결합되며 효과적인 classifier를 만들 수 있다고 하여 기존 알고리즘을 변형하여 사용한다.
(레알 집단지성이다..!ㅋㅋㅋㅋ)
이러한 때문에 feature를 찾는 것이 중요하다.
그래서 weak learning 알고리즘은 positive(얼굴 有)와 negative(얼굴 無) example을 나눈 single rectangle feature를 선택하도록 설계되었다. weak learner는 각 feature에 대해 최적의 threshold(임계값) classification function을 결정하도록 하여 최소의 example 수가 잘못 분류되게 한다.

수식에서 h(x)는 weak classifier, f는 h(x)를 구성하는 feature, θ는 threshold, p는 parity(부등호 기호 방향을 나타냄)를 나타낸다.
h(x)의 값이 1이 나오면 feature가 특징을 잘 나타낸다는 뜻이고
h(x)의 값이 0이 나오게 되면 input한 이미지의 feature를 표현하지 못한다는 것이다.
결국 학습이 진행되며 0과 1의 binary 수가 선형으로 결합되며 weak classifier가 strong classifier로 진화한다!

그림 1은 Adaboost가 선택한 첫 번째, 두 번째 feature이다.
첫 번째 feature는 눈 영역과 광대 윗 부분 영역의 밝기 차이를 측정한 것이다. 첫 번째 결과는 눈 부위가 광대 윗부분보다 어둡다는 특징을 이용해 feature로 나온 것이다.
두 번째 feature는 눈 영역과 콧등 영역의 밝기 차이를 비교한 결과이다. 아마 이 결과도 눈 부위가 콧등보다 어둡다는 특징을 이용한 결과일 것이다.
The Attentional Cascade
Cascade
Cascade는 입력되는 이미지나 영상에 감지하고자 하는 부분(얼굴이라든지,, 행동이라든지,, 포즈라든지,,)을 제외한 나머지 부분을 줄여서 감지하고자 하는 부분에만 strong classifier를 통과시켜 최종 결과를 찾는 방식을 말한다.
그래서 처리 속도를 빠르게 할 수 있다.
생각해보면 얼빡샷이 아니고서야 내 얼굴보다 다른 영역이 큰건 당연한 것이다. 예를 들자면 30~40명 되는 초등학교 때 찍은 반 단체사진에서 내 얼굴은 그저.. 소금 한 알... (키 크다고 매번 맨 뒤로 보내진...)
그래서 시간낭비 전력낭비 하지말고 딱 필요할 것 같은 부분만 strong classifier를 통과시키는 방법을 사용하여 비용을 아낄 수 있게 된다.
논문은 이 방법을 cascade 단계를 Adaboost를 이용한 training classifier로 구성하고 false negative를 최소화 하는 threshold를 조정한다.
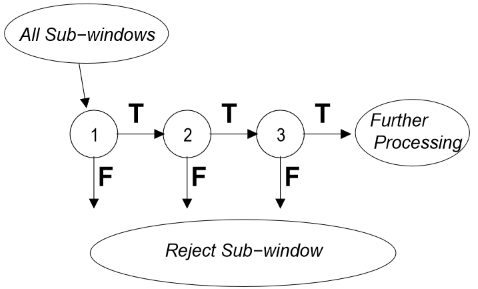
그림 4는 cascade 과정을 나타낸 것이다.
첫 번째 classifier에 sub-window가 들어가면
얼굴인 경우=> T로 분류되어 다음 단계 classifier로
얼굴이 아닐 경우=> F로 분류되어 sub-window가 거부되고 cascade에서 안녕~!이 된다.
T로 분류된 sub-window는 T로 분류되면 분류될 수록 더 강한 strong classifier를 만나며 분류된다.
그래서 단계가 진행될 수록 sub-window 수는 줄어들게 된다.
참고
https://www.youtube.com/watch?v=_QZLbR67fUU
주저리
이 논문이 2001년에 발행되었는데, 아직도 object detection에 있어 수학의 정석과 같은 존재라는 것이 신기했다.
그만큼 잘 만들어진 알고리즘이라는 뜻일 것이다.
Adaboost 부분에서는 단순히 adaboost 알고리즘을 그대로 가져다 쓰는 것이 아니라, face detection을 더욱 효율적으로 하기위해 weak classifier와 feature로 초점을 바꿀 수 있다는 사실이 흥미로웠다.
그리고 영어공부는 번역기가 완벽해지지 않는 이상 계속 해야겠다^_^ㅎㅎ



